all AI news
Scrape Google Flights with Python
April 21, 2023, 10:40 a.m. | Artur Chukhrai
DEV Community dev.to
- What will be scraped
- Full Code
- Preparation
Code Explanation- Working with a Playwright
- Get page
- Scrape Google Flights Listings
- Output
- Links
What will be scraped
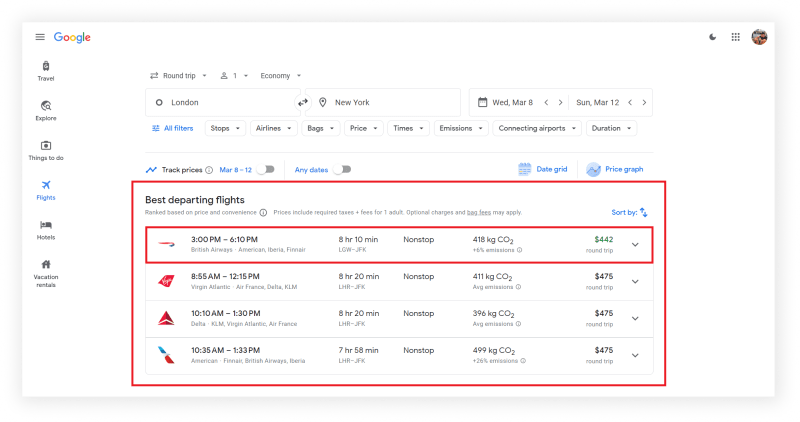{kind=link}
Full Code
from playwright.sync_api import sync_playwright
from selectolax.lexbor import LexborHTMLParser
import json, time
def get_page(playwright, from_place, to_place, departure_date, return_date):
page = playwright.chromium.launch(headless=False).new_page()
page.goto('https://www.google.com/travel/flights?hl=en-US&curr=USD')
# type "From"
from_place_field = page.query_selector_all …click code false google headless import json keyboard launch playwright programming python sleep tutorial type webscraping
More from dev.to / DEV Community
Jobs in AI, ML, Big Data
Data Architect
@ University of Texas at Austin | Austin, TX
Data ETL Engineer
@ University of Texas at Austin | Austin, TX
Lead GNSS Data Scientist
@ Lurra Systems | Melbourne
Senior Machine Learning Engineer (MLOps)
@ Promaton | Remote, Europe
Software Engineering Manager, Generative AI - Characters
@ Meta | Bellevue, WA | Menlo Park, CA | Seattle, WA | New York City | San Francisco, CA
Senior Operations Research Analyst / Predictive Modeler
@ LinQuest | Colorado Springs, Colorado, United States